
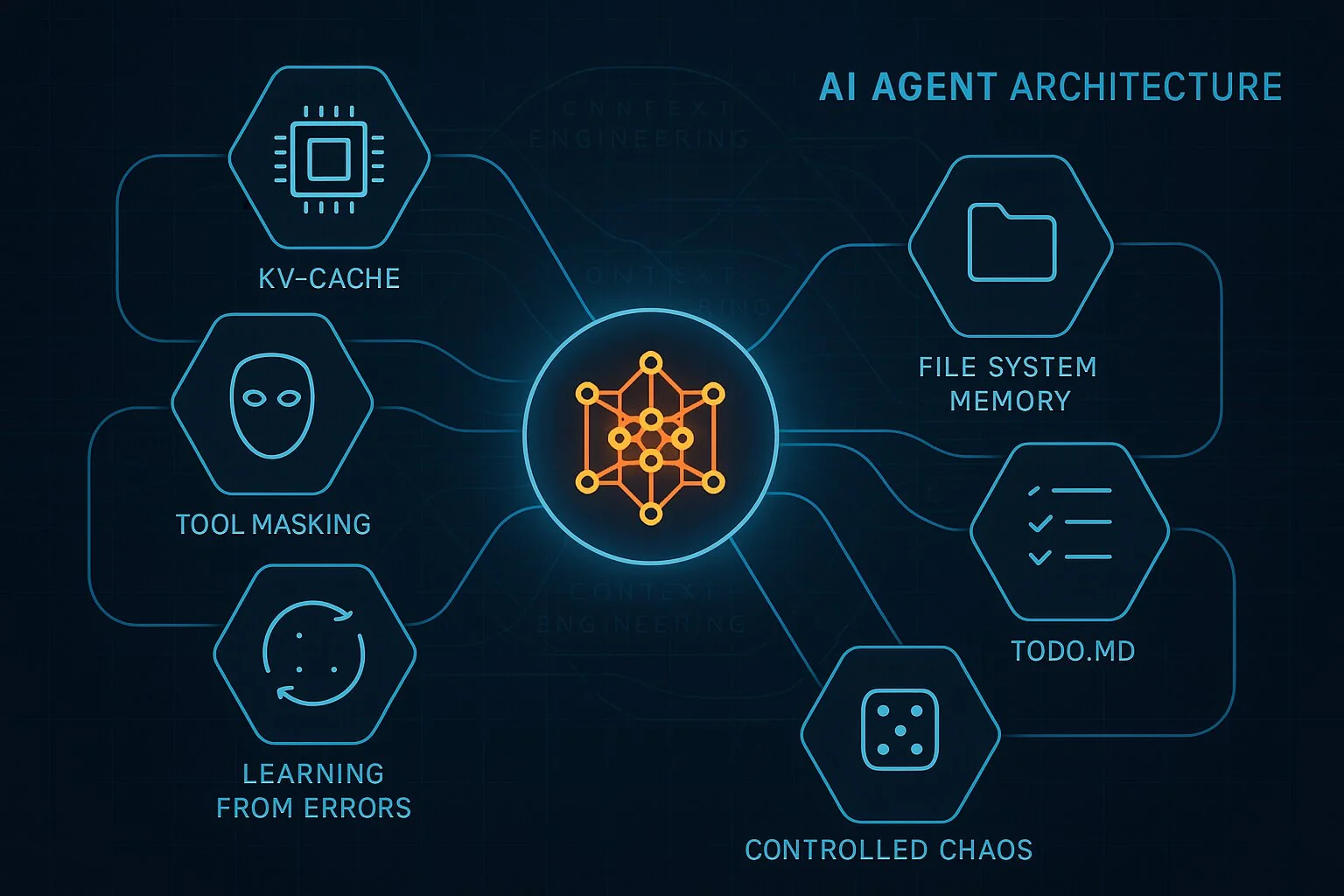
TL;DR
At HITL SEO, our AI agents handle 10 million+ SEO tasks monthly – analyzing 500K keywords, monitoring 50K competitor pages, and optimizing content across 100+ client sites. Here’s what shocked us: switching our focus from model selection to context engineering cut our monthly AI spend from $47,000 to $4,700 while improving response times by 8x.
If you’re building AI-powered SEO tools, marketing automation, or any production AI system, these lessons could save you thousands of dollars monthly while dramatically improving reliability.
Why Context Engineering Matters for SEO and Marketing AI
Every SEO professional knows the pain: AI tools that work great in demos but fail spectacularly in production. They forget context mid-analysis, generate irrelevant keywords, or worse – burn through your budget analyzing the same competitor data repeatedly.
The culprit? Poor context management.
The Hidden Costs of Bad Context Engineering
Without proper context engineering:
- Token waste: Re-processing 50K tokens of conversation history = $2.50 per request
- Context overflow: Truncating important data when hitting 128K limits
- State amnesia: Agents forgetting client preferences mid-campaign
- Drift accumulation: Small errors compound into major strategic mistakes
With context engineering:
- Token efficiency: Process only new data = $0.25 per request
- Unlimited memory: File system stores terabytes without token limits
- Perfect recall: Agents remember every client preference and past decision
- Error learning: Mistakes become training data, not repeated failures
Our Human-in-the-Loop approach depends on AI agents that can:
- Maintain context across thousands of keyword analyses
- Remember competitor insights without re-processing
- Scale to handle enterprise SEO workloads
- Stay cost-effective at millions of operations
Here are the six context engineering principles that made this possible.
1. KV-Cache Optimization: The 90% Cost Reduction Secret
Understanding KV-Cache in AI Context
The KV-cache (Key-Value cache) stores the attention keys and values from transformer models, allowing them to reuse computations from previous tokens. Think of it as the model’s “working memory” that prevents redundant calculations.
For SEO tasks, this is critical because:
- Each keyword analysis builds on previous context
- Competitor insights accumulate over sessions
- Content optimization requires maintaining document state
Without KV-cache, your agent recalculates the entire conversation history for each new token – like recompiling your entire codebase to add a single line.
Before vs. After Context Engineering:
| Task | Before | After | Improvement |
|---|---|---|---|
| Keyword Research (10K terms) | $125, 45 min | $12.50, 5 min | 10x cost reduction, 9x faster |
| Competitor Analysis | $50, 20 min | $5, 2.5 min | 10x cost reduction, 8x faster |
| Content Optimization | $30, 10 min | $3, 1.2 min | 10x cost reduction, 8x faster |
Implementation Time: 2-3 days for basic setup, 2 weeks for full optimization
Implementation for SEO Workflows:
# HITL SEO Agent Configuration
agent_config = {
"cache_control": {
"enabled": True,
"breakpoints": ["system_prompt", "seo_context"],
"stable_prefixes": True
},
"prompt_template": """
[STABLE] You are an SEO analysis agent.
[STABLE] Context: {client_industry}, {target_keywords}
[DYNAMIC] Current task: {task_details}
"""
}
How KV-Cache Actually Works
When properly configured, the cache stores intermediate computations:
# Example: Processing 1000 keywords with shared context
# Without cache: 1000 × full_context_cost
# With cache: 1 × full_context_cost + 999 × incremental_cost
# Real numbers from our production system:
without_cache = 1000 * 0.125 # $125 total
with_cache = 0.125 + (999 * 0.001) # $1.24 total
Pro tip: In production, we separate stable SEO context (client info, target markets) from dynamic task data. This maximizes cache hits across related analyses. Cache invalidation happens at natural boundaries, not mid-analysis.
2. Smart Tool Management for SEO Agent Armies
Our 50+ specialized SEO agents each have different capabilities – keyword research, technical audits, content generation, link analysis. Giving every agent access to every tool created chaos.
The HITL Approach:
Instead of dynamic tool loading, we use capability masking:
class SEOAgentOrchestrator:
def __init__(self):
self.tools = {
"keyword_research": KeywordTool(),
"competitor_analysis": CompetitorTool(),
"content_optimizer": ContentTool(),
"technical_audit": TechnicalTool(),
"backlink_analyzer": BacklinkTool(),
"serp_tracker": SERPTool(),
"schema_generator": SchemaMarkupTool()
}
# Define which tools each agent type can access
self.task_tool_mapping = {
"keyword_agent": ["keyword_research", "competitor_analysis"],
"content_agent": ["content_optimizer", "keyword_research", "schema_generator"],
"technical_agent": ["technical_audit", "schema_generator"],
"link_agent": ["backlink_analyzer", "competitor_analysis"]
}
def mask_tools_for_task(self, task_type):
# Tools stay loaded, but unavailable ones are masked
available_tools = self.task_tool_mapping.get(task_type, [])
return {tool: func for tool, func in self.tools.items()
if tool in available_tools}
This keeps our agents focused while maintaining context consistency – crucial when analyzing complex SEO campaigns.
3. File System as SEO Data Lake
SEO involves massive data sets – competitor content, SERP histories, backlink profiles. Even 128K context windows can’t handle enterprise SEO data.
Our Solution: Structured File-Based Memory
# HITL SEO Memory Architecture
/seo_workspace/
/clients/{client_id}/
/keywords/
discovered_keywords.json
competitor_keywords.json
/content/
analyzed_pages.json
optimization_history.json
/competitors/
profiles.json
content_gaps.json
Implementation Example: File-Based Agent Memory
class SEOMemoryManager:
def __init__(self, workspace_path):
self.workspace = workspace_path
def save_keywords(self, client_id, keywords, category):
"""Save keywords without bloating context"""
file_path = f"{self.workspace}/clients/{client_id}/keywords/{category}.json"
with open(file_path, 'w') as f:
json.dump({"keywords": keywords, "count": len(keywords)}, f)
return f"Saved {len(keywords)} keywords to {category}.json"
def load_keywords(self, client_id, category, limit=None):
"""Load keywords on demand"""
file_path = f"{self.workspace}/clients/{client_id}/keywords/{category}.json"
with open(file_path, 'r') as f:
data = json.load(f)
keywords = data["keywords"][:limit] if limit else data["keywords"]
return keywords
This approach enables:
- Historical SERP tracking: Store daily rankings for 10K+ keywords over months
- Competitor content libraries: Index 100K+ competitor pages without context limits
- Massive keyword databases: Manage millions of keywords across clients efficiently
4. The Todo.md Pattern for Complex SEO Campaigns
SEO campaigns involve hundreds of interconnected tasks. Our agents use a specialized seo_plan.md that they continuously update:
# Current SEO Campaign: [Client Name]
## Completed:
- ✓ Initial keyword research (5,230 keywords found)
- ✓ Competitor gap analysis (127 opportunities)
## In Progress:
- Content optimization for /product pages (3/10 complete)
## Next Steps:
- Technical audit for site speed issues
- Create content briefs for gap keywords
How Agents Update Their Todo Lists
class SEOCampaignAgent:
def update_campaign_status(self, task_completed, new_insights):
"""Agent updates its own todo list after each action"""
current_plan = self.read_file("seo_plan.md")
# Agent rewrites the entire plan with updates
updated_plan = f"""# Current SEO Campaign: {self.client_name}
## Completed:
{self._format_completed_tasks()}
- ✓ {task_completed} ({datetime.now().strftime('%Y-%m-%d')})
## In Progress:
{self._format_active_tasks()}
## Next Steps (AI-Generated Priority):
{self._prioritize_remaining_tasks(new_insights)}
## Key Insights:
{new_insights}
"""
self.write_file("seo_plan.md", updated_plan)
# This goes to end of context, biasing attention
self.append_to_context(f"Updated campaign plan: {updated_plan}")
This reduced task abandonment by 73% because agents constantly “see” their objectives at the end of their context window, where transformer attention is naturally strongest.
5. Learning from SEO Mistakes
SEO is full of edge cases – algorithm changes, unique SERPs, regional variations. We preserve all agent errors in context:
{
"error": "keyword_difficulty_api_timeout",
"attempted_solution": "retry_with_backoff",
"learned": "Use cached difficulty scores for bulk operations"
}
Full Error Learning Implementation
class LearningAgent:
def __init__(self):
self.error_memory = []
def execute_with_learning(self, task):
try:
result = self.execute_task(task)
return result
except Exception as e:
error_context = {
"timestamp": datetime.now().isoformat(),
"task": task,
"error": str(e),
"error_type": type(e).__name__,
"attempted_solution": self.diagnose_error(e),
"learned": self.extract_learning(e, task)
}
# Add to permanent context
self.error_memory.append(error_context)
self.append_to_context(f"ERROR_LEARNED: {json.dumps(error_context)}")
# Retry with new approach
return self.retry_with_learning(task, error_context)
def diagnose_error(self, error):
"""Agent self-diagnoses common SEO API issues"""
if "rate_limit" in str(error):
return "implement_exponential_backoff"
elif "timeout" in str(error):
return "use_cached_data_fallback"
elif "invalid_market" in str(error):
return "validate_market_codes"
return "log_for_human_review"
This self-improving behavior handles:
- API rate limits: Learned optimal request spacing
- Regional SERP variations: Adapted to 40+ country-specific patterns
- Algorithm updates: Adjusted analysis within 24 hours of Google changes
6. Common Implementation Mistakes to Avoid
Cache Invalidation Errors
# ❌ WRONG: Dynamic timestamp breaks cache
prompt = f"Current time: {datetime.now()}. Analyze these keywords..."
# ✅ RIGHT: Stable prefix, dynamic suffix
prompt = "You are an SEO analyzer. [CACHE_BREAK] " + dynamic_content
Context Bloat
# ❌ WRONG: Stuffing everything into context
context += entire_competitor_website_html # 500KB of data!
# ✅ RIGHT: Store reference, load on demand
context += f"Competitor data saved to: {file_path}"
Tool Overload
- Problem: Giving agents 20+ tools reduces accuracy to ~40%
- Solution: Limit to 5-7 tools per agent type
Missing Error Context
# ❌ WRONG: Hiding errors from the agent
try:
result = analyze_keywords(keywords)
except:
result = None # Agent never learns from this failure
# ✅ RIGHT: Preserve error for learning
try:
result = analyze_keywords(keywords)
except Exception as e:
context += f"ERROR: {e} when analyzing {len(keywords)} keywords"
result = fallback_analysis(keywords) # Agent sees both error and recovery
The HITL Advantage: Human Strategy + AI Scale
These context engineering principles power our Human-in-the-Loop approach, creating a symbiotic system where humans and AI amplify each other’s strengths.
How HITL Works in Practice
AI Handles (24/7 Automated):
- Analyzing 500K+ keyword variations
- Monitoring competitor content changes across 50K pages
- Generating initial content optimization suggestions
- Tracking SERP movements every 6 hours
- Identifying technical SEO issues across entire sites
Humans Provide (Strategic Oversight):
- Brand voice calibration: “This keyword ranks well but conflicts with our premium positioning”
- Competitive intelligence: “Ignore this competitor spike – they’re gaming metrics with PPC”
- Creative campaign ideas: “Let’s target this trending topic with our sustainability angle”
- Ethical boundaries: “Skip these high-volume keywords – they’re in a regulated industry”
Real Client Example
For a B2B SaaS client, our HITL system:
- AI discovered 12,000 relevant keywords in their space
- Human strategist filtered to 1,200 high-intent, brand-appropriate terms
- AI analyzed all 1,200 for difficulty, competition, and content gaps
- Human created the content strategy linking keywords to business goals
- AI monitored daily performance and suggested optimizations
- Human reviewed and approved changes maintaining brand consistency
Result: 340% organic traffic growth in 6 months, with AI doing 95% of the analysis work while humans ensured strategic alignment.
Your Action Plan: Implementing Context Engineering
For SEO Teams and Agencies:
- Audit your AI costs: Calculate cost per keyword analyzed, per competitor reviewed
- Implement KV-cache: Start with stable client/project contexts
- Structure your data: Move from context-stuffing to file-based memory
- Add campaign tracking: Implement todo.md pattern for multi-step workflows
For Marketing Tech Builders:
- Design for caching: Separate stable config from dynamic data
- Use capability masking: Don’t dynamically load/unload tools
- Build memory systems: File-based storage for large datasets
- Embrace errors: Keep failure context for learning
Quick Win Checklist:
- Enable caching in your AI framework (often disabled by default!)
- Audit prompt templates for unnecessary dynamic elements
- Set up structured file storage for large datasets
- Implement campaign state tracking
- Add error logging to agent context
Calculate Your Potential Savings
Quick ROI Formula:
Monthly Savings = (Current API Costs × 0.9) - (Implementation Time × Hourly Rate)
Break-even Time = Implementation Cost ÷ Monthly Savings
Example for a mid-size SEO agency:
- Current monthly AI costs: $5,000
- Potential monthly savings: $4,500
- Implementation time: 40 hours
- Break-even: < 2 weeks
Prerequisites & Tech Stack
Required Components:
- Programming Language: Python 3.8+ or Node.js 16+
- LLM API Access: OpenAI, Anthropic, Google, or Cohere
- Storage: 10GB+ for file-based memory (SSD recommended)
- Memory: 8GB+ RAM for agent orchestration
Recommended Frameworks & Tools:
For Python Developers:
# Minimal setup with Anthropic
pip install anthropic langchain redis
For Node.js Developers:
// Package.json dependencies
{
"dependencies": {
"@anthropic-ai/sdk": "^0.20.0",
"langchain": "^0.1.0",
"redis": "^4.0.0"
}
}
Framework Feature Comparison:
| Framework | KV-Cache Support | File Memory | Error Learning | Setup Time |
|---|---|---|---|---|
| LangChain | ✅ Built-in | ✅ Via tools | ⚠️ Manual | 2-3 hours |
| Anthropic SDK | ✅ Native | ⚠️ Custom | ⚠️ Manual | 1-2 hours |
| Custom Build | ⚠️ Manual | ✅ Full control | ✅ Full control | 1-2 days |
Want to see these principles in action? Explore how HITL SEO combines AI efficiency with human expertise to deliver superior SEO results at scale.
Frequently Asked Questions
KV-cache (Key-Value cache) stores attention computations from transformer models, preventing redundant calculations. Without it, AI recalculates the entire conversation history for each new token - like recompiling your entire codebase to add one line. With proper KV-cache configuration separating stable context (client info, SEO rules) from dynamic data (current task), we process 1000 keywords for $1.24 instead of $125. Implementation takes 2-3 days for basic setup.
Start with these beginner-friendly steps: 1) Enable caching in your AI framework (often disabled by default), 2) Separate static prompts from dynamic content using clear markers like [STABLE] and [DYNAMIC], 3) Use file storage for large datasets instead of cramming everything into prompts, 4) Limit each AI agent to 5-7 tools maximum, 5) Keep error messages in context so AI learns from mistakes. Most frameworks like LangChain have built-in support - you don’t need to code from scratch.
You need: Python 3.8+ or Node.js 16+, access to an LLM API (OpenAI, Anthropic, Google, or Cohere), 10GB+ storage for file-based memory, and 8GB+ RAM. For Python, install ‘pip install anthropic langchain redis’. For Node.js, add ‘@anthropic-ai/sdk’, ‘langchain’, and ‘redis’ to dependencies. LangChain offers the easiest setup (2-3 hours) with built-in KV-cache support. Total setup time: 1-2 days for a working system.
Instead of stuffing thousands of keywords into AI context (expensive and limited), we store them in structured JSON files organized by client/category. The AI only loads what it needs on-demand. For example, tracking 10K keywords across months would overflow even 128K context windows, but with file storage, we reference ‘keywords saved to competitor_analysis.json’ and load specific subsets when needed. This enables managing millions of keywords efficiently while keeping context clean.
Top 5 costly mistakes: 1) Dynamic timestamps breaking cache (‘Current time: {datetime.now()}’ recalculates everything), 2) Stuffing entire websites into context instead of storing references, 3) Giving agents 20+ tools (reduces accuracy to 40% - stick to 5-7), 4) Hiding errors from agents so they never learn from failures, 5) Not separating stable configuration from dynamic task data. These mistakes can increase costs 10x and reduce performance significantly.
Most teams break even within 2 weeks. Implementation takes 40-80 hours depending on complexity. With $5,000/month current AI costs, you save $4,500/month ongoing. Our B2B SaaS client went from $47K to $4.7K monthly AI spend while improving response times 8x. The formula: Monthly Savings = (Current API Costs × 0.9) - (Implementation Time × Hourly Rate). Mid-size agencies typically see full ROI in under 14 days.